Most AI pilots are built on a flawed process. Here's where it breaks.

What. Most organizations rolling out AI follow the same six-stage, IT-led process they've used for every major technology implementation: scope, data preparation, model development, testing, deployment, monitoring. It looks sensible. But it contains a structural flaw, and that flaw causes projects to fail at the same point again and again.
So what. The model performs. Testing looks strong. Then the organization tries to absorb it — and it can't. Existing workflows weren't built for it. The people expected to use it don't understand what it's doing or why. No one owns the change. The obstacles were obvious. They just weren't visible until the cost of doing something about them was at its highest.
Now what. There are three predictable causes behind this failure. Once you can spot them, you can redesign the process before a single line of code gets written. That's what this article is about.
The standard AI deployment process — and where it breaks
Many organizations approach AI deployment through a familiar IT-led lifecycle. It moves through six stages in order: define the problem, prepare the data, build the model, test it, deploy it into the organisation, then monitor it.
On paper, it makes perfect sense. In reality, it contains a structural weakness that causes many AI rollouts to die at the same point.
The model works. The tests are positive. The team feels good about what they’ve built. Then it’s time to deploy it — and the organization can’t take it in. It doesn’t fit existing workflows. The people expected to use it and trust it don’t understand what the AI is doing or how it reached its output. No one owns the change. So the model sits there: technically live, practically unused.
This is where most AI rollouts fail. Not because the technology didn’t work, but because the organization was never prepared to use it.
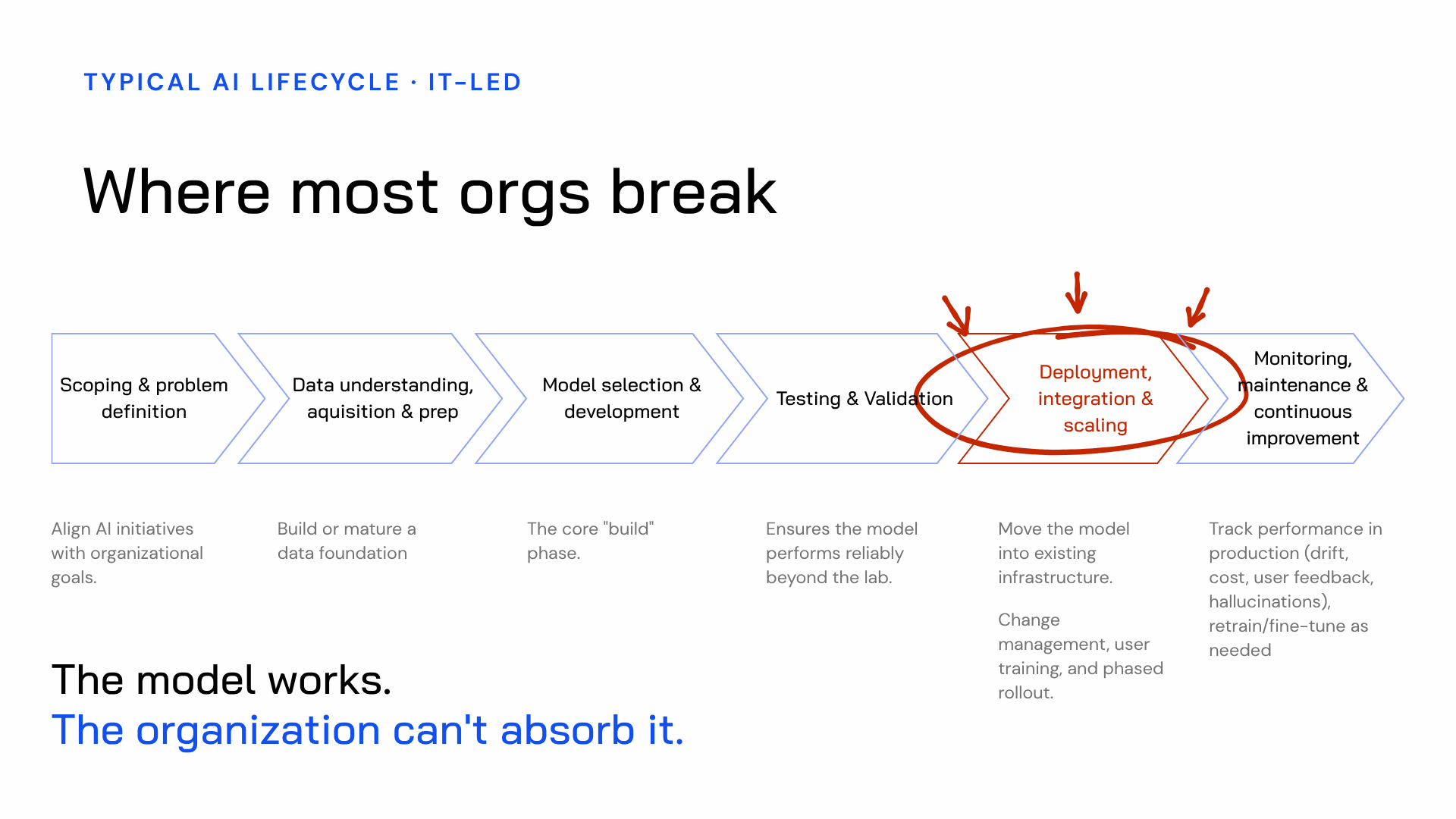
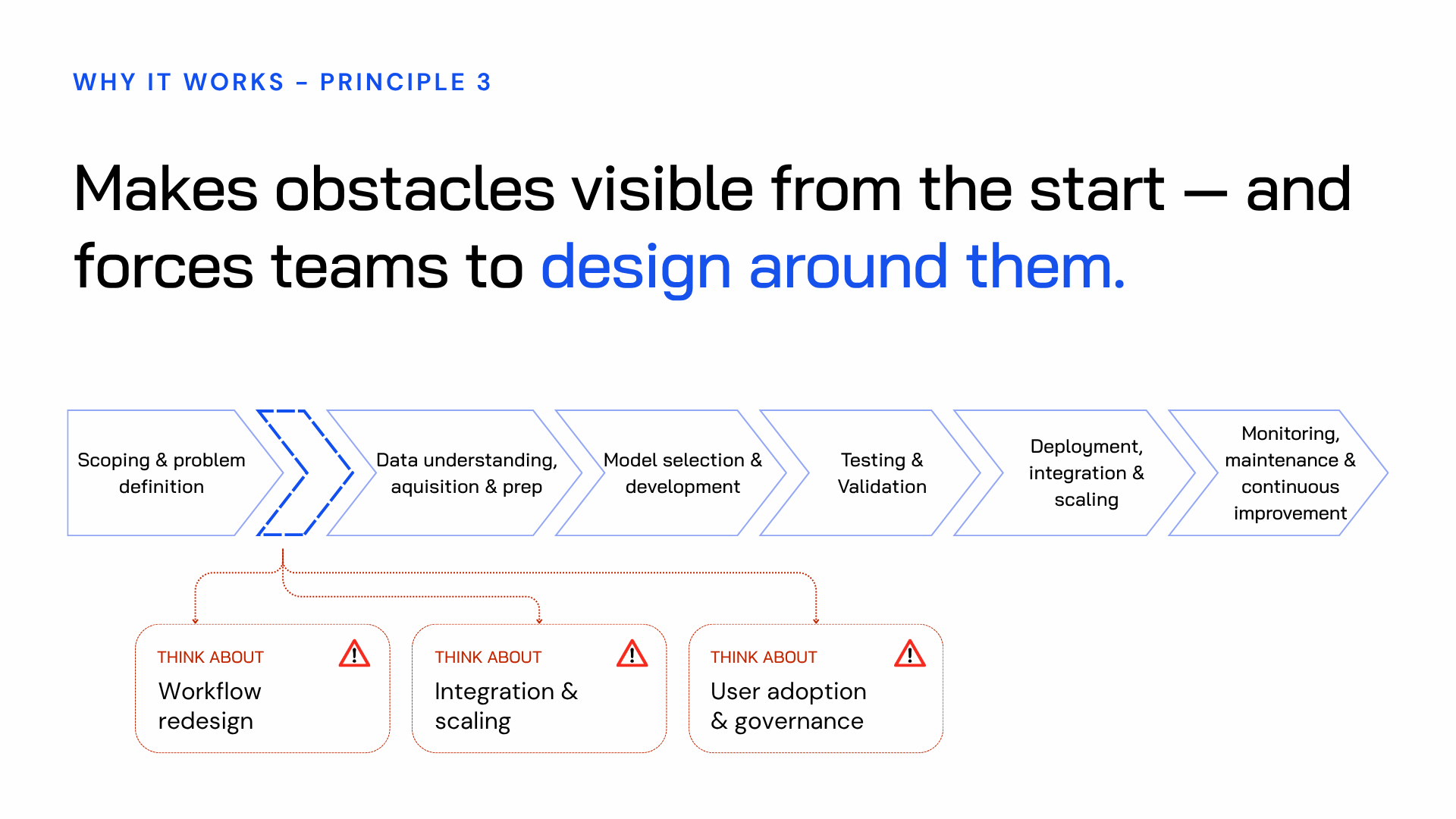
What makes this so frustrating is that the blockers were there from the start. Legacy tech debt. Fragile workflows. Unclear ownership. Teams with very different levels of technical confidence. None of these issues appear out of nowhere. They were always present. The problem is that the standard IT-led process doesn’t bring them into view until it’s too late and too expensive to design around them.
So the real question is this:
If the obstacles are so predictable, why do organizations still miss them?
The answer lies in the structure of the process itself. And it comes down to three root causes.
Root cause 1: the thinking happens in sequence
The IT-led lifecycle runs in stages. IT scopes the problem. IT selects the model. IT tests it. And then, at stage five — deployment — everyone else gets to deal with it.
That includes the workflow owners, the legal team, the people doing the work every day, the managers who have to explain what is changing and why, and the L&D team that must train people and maintain standards.
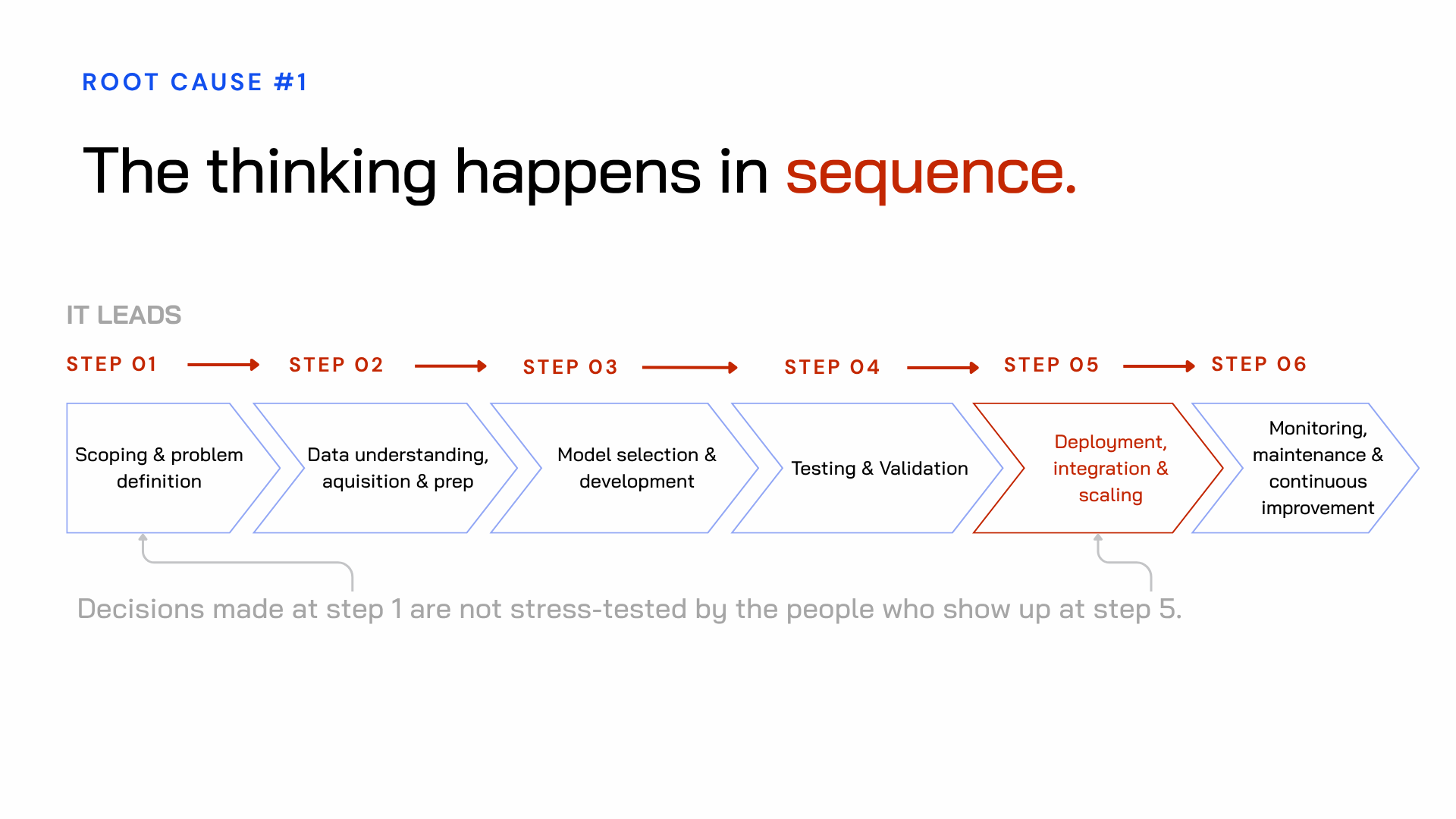
But the decisions that affect all of them were already made back at stage one, during scoping, without them in the room. By the time they're brought in, the architecture is fixed. The model is built. The constraints are already locked in. Reworking it is costly. So the organization ends up trying to absorb a solution it had no role in shaping.
This is a structural failure of the build process itself.
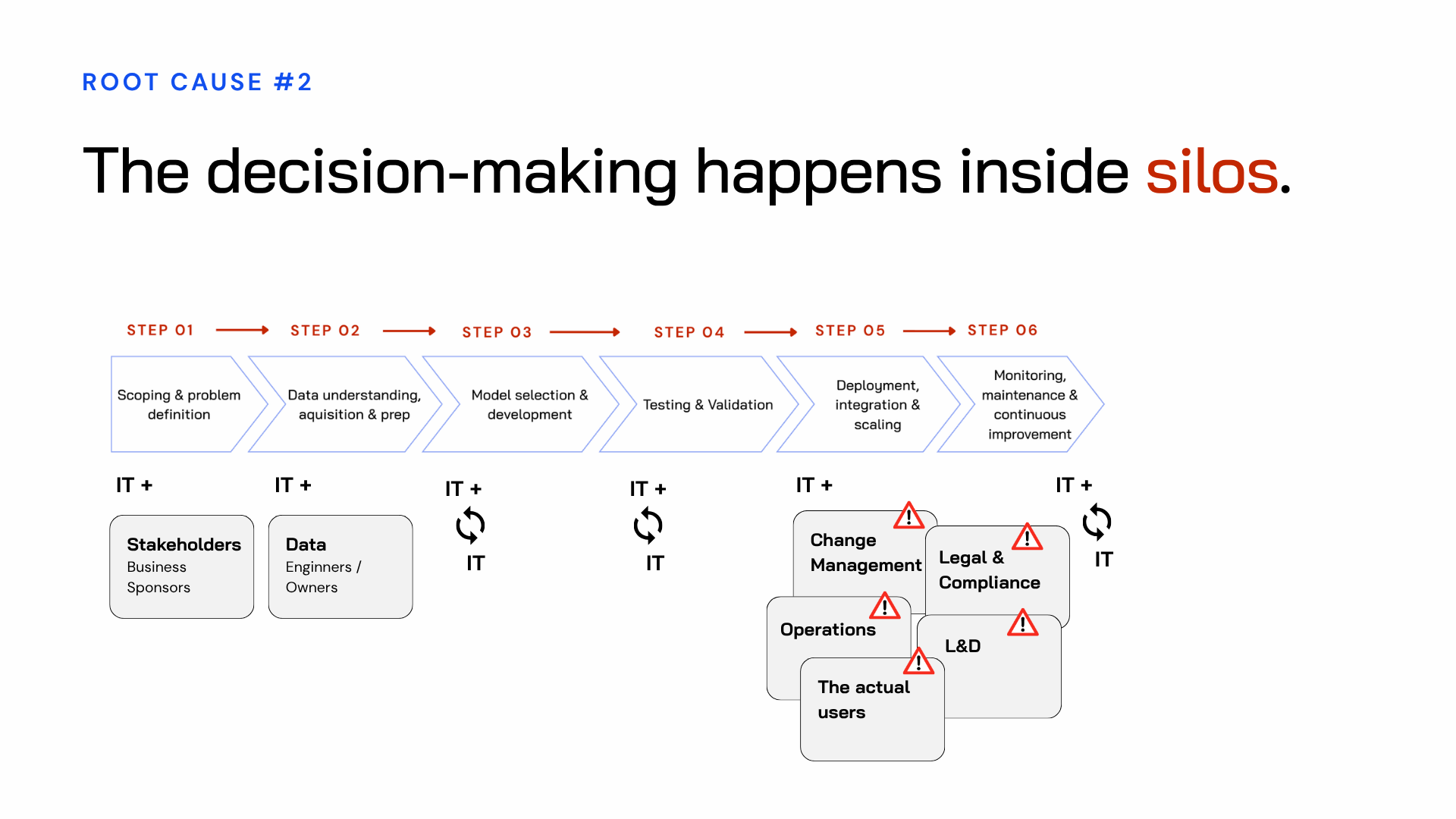
Root cause 2: the right people are never in the room at the same time
Even within the stages where collaboration does happen, it's rarely cross-functional in any meaningful way.
At the start, IT may work with senior business stakeholders to scope the opportunity. Then, through development and testing, IT works mainly with data engineers and often mostly on its own. By deployment, the team suddenly needs change management, legal, L&D, operations, and the actual end users. Each of those groups brings constraints, concerns, and context that should have shaped the design from the beginning.
The person who understands the workflow has never spoken to the person who understands the data. The person who knows the compliance landscape has never sat down with the person who understands the model’s limitations. Everyone makes decisions from their own partial view. The gaps only become obvious at deployment, when those partial views are expected to line up.
That gap — between the people who built the solution and the people who have to live with it — is where rollouts collapse.
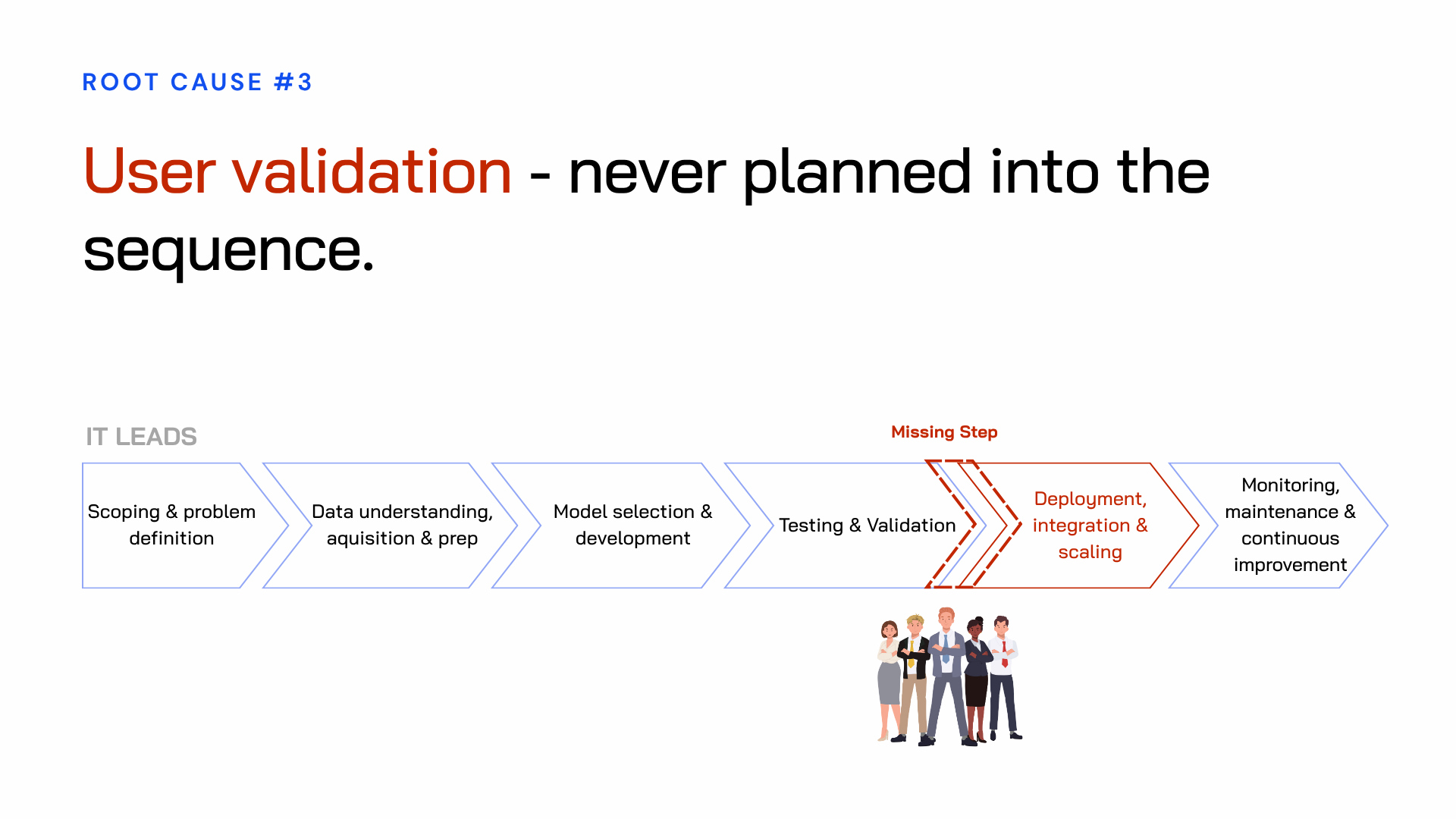
Root cause 3: user validation is never planned in
This is the one that surprises people most.
The employees whose work is being changed — the people who will use this AI day after day — are rarely given a structured point in the process to test it, react to it, or challenge it before it is built.
There’s no formal user validation. No point where a real employee sits with the system and tells the team whether it actually makes the work easier or introduces new friction. All of that gets discovered during deployment, at full cost, with the whole organization now involved.
It's not that organizations don't believe user feedback matters. It's that the IT-led sequence has no natural place to put it. So it gets left out. The assumption becomes: if the solution is technically strong and senior stakeholders have signed off on it, adoption will take care of itself.
It usually doesn’t.
Why Agencies and Consultancies hit the same wall
The IT-led route is the most common, but it isn’t the only one that runs into this issue.
Organizations that hire an automation agency often hit a similar problem. Agencies are skilled at building, but their business model is centered on the build itself. Discovery gets shortened so the project can move into execution, because that's where revenue sits. The questions that need answering before anything is built — is this the right workflow, will people actually use it, what happens to the surrounding roles — often don't get enough attention. Redesigning how people work around AI usually sits outside the agency's remit.

Organizations that bring in a large consultancy for AI strategy face a different version of the same gap. They get strong thinking: robust research, useful frameworks, and a prioritized set of recommendations. What they often don't get is ownership. The people expected to execute the strategy weren't involved in building it. So when the consultants leave, the organization is left with documents and recommendations, but not with an internal capability that can carry the work through.

All three paths fail in the same place: no one owns the step in between.
The decision-making before the build.
The redesign of the workflow.
The validation that turns a promising idea into something worth investing in.
What if you could surface all of these obstacles earlier?
That’s the design challenge the AI Workflow Sprint is built to solve.
The sprint sits at the very beginning of the IT-led lifecycle — between scoping and everything else. Its job is to resolve the ambiguity that kills most rollouts before it has a chance to become expensive. It replaces the part of the process where the right people aren't in the room and the right questions aren't being asked.

When the sprint is done, IT has a validated brief. The obstacles that would have killed the rollout at stage five are visible at stage one, when you can still design around them. The goal isn't to block progress — it's to create the right conditions for progress to stick.
Some organizations try to get to the same place through a series of meetings. The problem is that meetings are usually unstructured, untimed, and ungoverned. They may eventually uncover the right questions, but there is no clear mechanism for making decisions, no obvious ownership, and no defined timeline. It's entirely possible to spend more time and more money reaching the same conclusions than the sprint would have cost in the first place.
The AI Workflow Sprint — even though it's delivered as a workshop — produces something tangible: a redesigned workflow, a working AI Agent MVP, and a clear decision from the people who own the initiative: scale, iterate, or stop. All within a defined timeline and a defined cost.
How the sprint principles help fix each root cause
Root cause 1 (sequential thinking) → all expertise in the room from day one
The sprint brings together a cross-functional team — the AI Discovery Pod — for the first two days.
Six to eight people who collectively hold everything the redesign needs: the AI engineer who understands what the model can realistically produce, the workflow owner who knows the exceptions no document ever captures, legal and compliance, the Decider who owns the outcome, the designer focused on the employee experience, and the business or process manager who sees how the work connects upstream and downstream.
They work together, not one after another. The constraints that would have surfaced at stage five become visible at stage one.

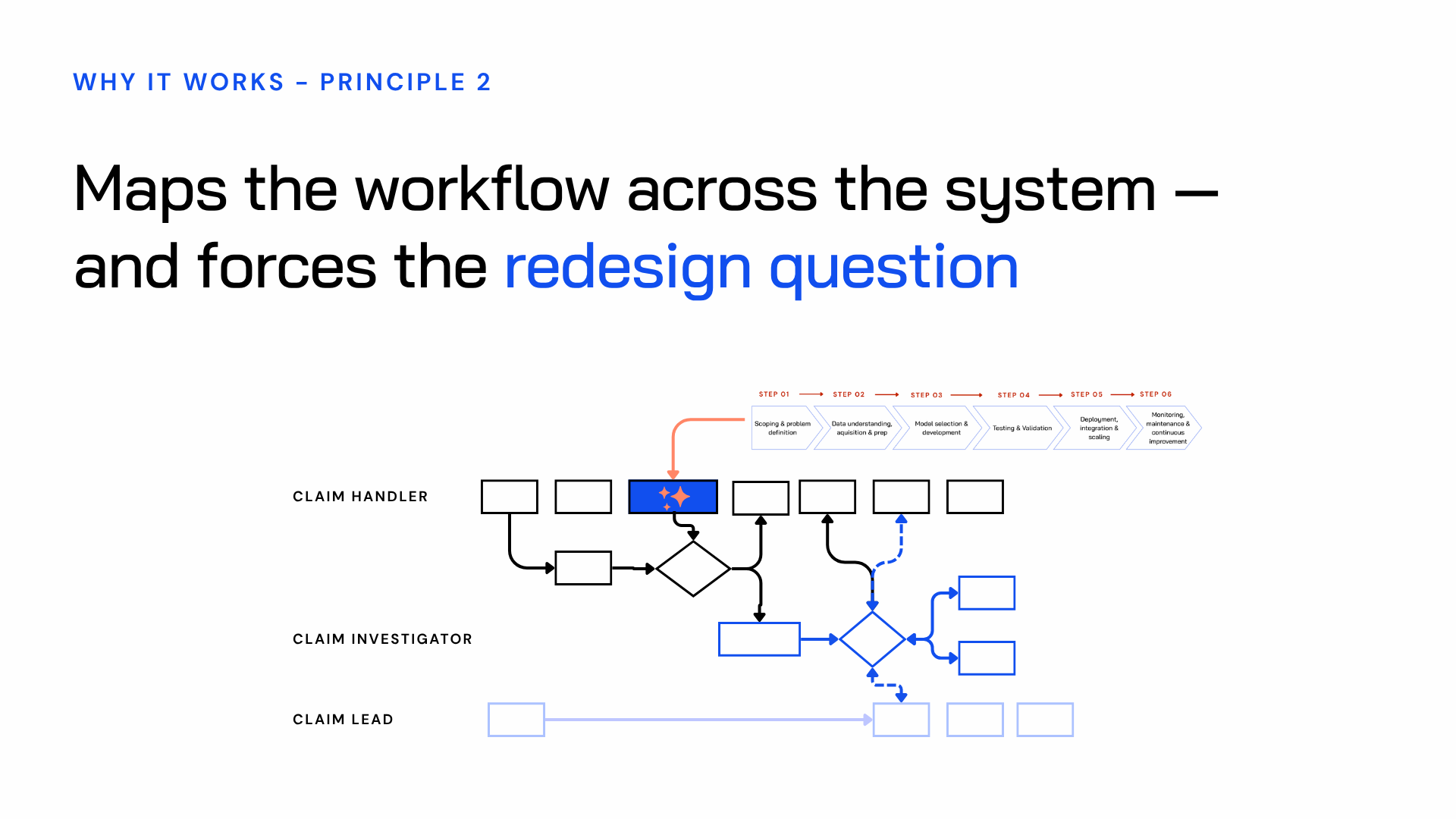
Root cause 2 (siloed decisions) → the workflow is mapped across the whole system
When a cross-functional team maps a workflow together for the first time, what they find is almost always a surprise.
Steps that belong to nobody. Handoffs that only function because one person has them memorized. Decisions made on instinct rather than process.
Put five people from the same workflow in one room and ask them to map it, and you'll often get five different versions. Not because anyone is wrong, but because each person sees the work from where they sit. The sprint creates one shared, complete map before any AI is introduced.
Root cause 3 (no user validation) → validation is built into the process, not added at the end
Day four exists for one reason: to find out how employees actually perceive this new AI intervention. Perception is reality.
Five structured conversations with five employees who know the workflow. The interviews aren't testing the technology — they're testing the experience, the attitudes, the trust. Does the employee understand what the AI is doing? Do they trust its output enough to use it? Does it actually improve the way they work?
At the end of day four, the Decider has real evidence from the people who need to make it work. Not assumptions. Not stakeholder opinions. Actual responses from the employees whose workflow this is supposed to improve. Scale, iterate, or stop — with confidence, not a gamble.
What happens during the AI Worflow Sprint?
Day 1 — Discovery: The full Discovery Pod maps how the work really happens today — not how it should happen on paper, but how it actually gets done. They build empathy with the employee whose workflow is being redesigned. And they produce a first-pass workflow redesign that cleans up the process before any AI is added.
Day 2 — Design: The team moves from understanding to design. They define what success at scale looks like — not just for this pilot, but if this works across the whole organization. They build a risk map, surfacing what could kill the rollout before they design around it. And they end with a storyboard: a frame-by-frame blueprint of exactly how the AI will interact with the employee. That storyboard is what the build team works from on day three.
Day 3 — Build: A smaller, focused team takes over — an AI engineer, a designer, and a subject matter expert. Their task is to turn the storyboard into something real enough to test. Not polished. Not production-ready. Just real enough for an employee to sit down with it and say whether it changes the way they work.
Day 4 — Validation: Five structured user interviews. The Decider gets real evidence. Scale, iterate, or stop.
You can read more about the full AI Workflow Sprint methodology here.
What you need before running an AI Workflow Sprint
The AI Workflow Sprint is not designed to begin from nothing. Before day one, the team needs a validated AI use case — something tied to a clear business priority, focused on a specific employee and workflow, and aimed at a problem worth solving.
If that clarity doesn’t exist yet, that’s where AI Problem Framing comes in.
Problem Framing determines what is worth doing. The sprint determines how to do it.
Running a sprint without a validated use case is like building a road before anyone has decided where it needs to go. You can have the best crew, the right materials, the most efficient process and still end up somewhere nobody wanted to be. Without a clear goal and real organizational support behind it, the sprint has no foundation. The Decider can't make a meaningful decision. The team can't align on what success looks like. The output exists, but nothing connects it to the business.

The people who can lead this are already in your organization
You do not need to bring in a large team of external facilitators to run an AI Workflow Sprint. In most organizations, the people who can facilitate it are already there: innovation managers, transformation leads, agile coaches, service designers, or anyone who already sits between leadership intent and team execution.
They already have the relationships, the credibility, and the access. What they need is the method.
If you're exploring how to build that capability internally, the AI Facilitator Training program teaches your team to run both AI Problem Framing and the AI Workflow Sprint independently so that every new workflow initiative doesn't need an external team to get it off the ground.
Request the training brochure →
Want to see this in action?
We ran a full webinar walking through exactly how the AI Workflow Sprint works — from the structural problems with the standard deployment process to what each day of the sprint produces.